I run one of the servers in the global NTP pool. I noticed something interesting in the data from the pool monitoring system, which determines which enlisted servers to include in the pool:
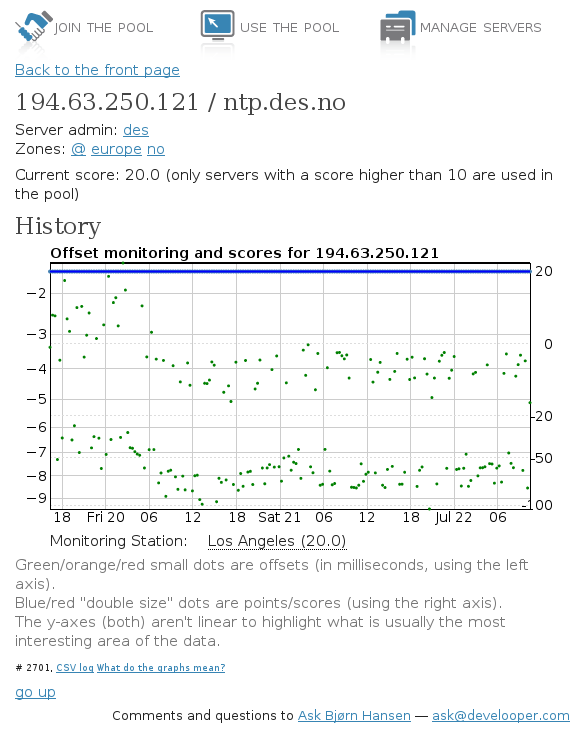
The blue line is the server’s score; the green dots show the offset in milliseconds between the time reported by my server and the monitoring system’s own clock. NTP uses a fairly simple algorithm to compensate for network latency; basically, it computes the round-trip delay and divides by two. A non-zero offset can mean one of three things:
- The client is synchronizing with this server, but hasn’t quite adjusted yet.
- The client is synchronizing with a different source and the two servers don’t agree on what the time is.
- The client is synchronizing with a different source and the two servers agree on what the time is, but the path between the client and one of the servers is asymmetric.
As far as I know, the monitoring system doesn’t synchronize with any of the servers it monitors, so either the second or third case applies. However, the graph clearly shows that the offset measured by the monitoring system alternates between two values (approximately -4 ms and -8 ms), with allowance for jitter. The only possible explanations for this are:
- The monitoring system keeps switching between two time sources that are 4 ms apart and synchronizes very quickly every time it switches.
- My server’s clock keeps switching between two time sources that are 4 ms apart and synchronizes very quickly every time it switches.
- The path taken by requests from the monitoring system to my server and responses from my server to the monitoring system varies, and one path is shorter than the other(s).
The NTP software used by the pool is designed to prevent the first two options, leaving only the third. This is not surprising to anyone familiar with the principles of Internet routing, but I don’t think I’ve ever seen such a clear demonstration of those principles. This graph would be a perfect exercise for a network communications class: “given the above description of the NTP protocol, explain why the offset switches alternates between two different values.”